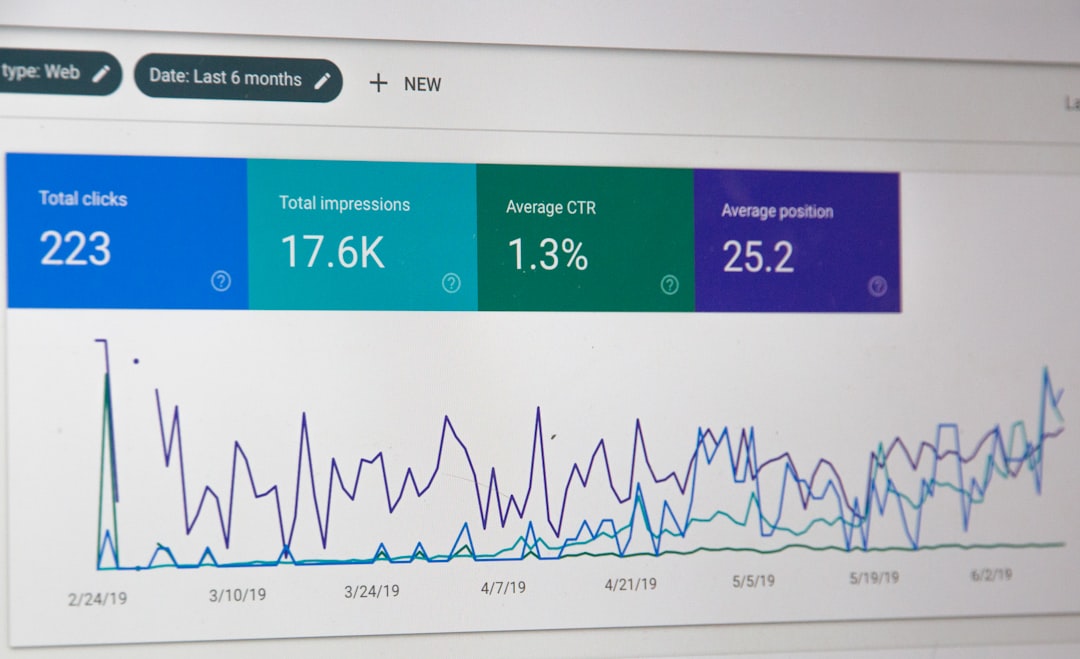
Every IT team knows the sound of chaos. It is the ping. Then another ping. Then twelve more pings. Soon, alerts are flying like popcorn in a microwave. Some are important. Many are not. This is where alert monitoring tools come in. They help teams see what matters, ignore the noise, and fix problems faster.
TLDR: Alert monitoring tools help IT teams cut through alert noise and see real problems clearly. They group related alerts, remove duplicates, and show what needs action first. This improves uptime, reduces stress, and gives teams better visibility across systems. In short, fewer false alarms and more useful signals.
Why Alerts Matter
Modern IT environments are busy places. There are servers. Apps. Databases. Networks. Cloud services. Containers. Security tools. Storage systems. And maybe one old machine in a closet that everyone is afraid to touch.
Each system can send alerts. That is good. Alerts tell you when something is wrong. A server is full. A service is down. A login looks strange. A payment system is slow. These things need attention.
But too many alerts can create a big problem. This problem is called alert fatigue. It happens when teams get so many alerts that they stop trusting them. They may miss the one alert that really matters.
Think of it like a smoke alarm that screams every time you make toast. After a while, you ignore it. That is risky. The same idea applies to IT.
The Big Problem: Too Much Noise
Alert noise is not just annoying. It is expensive. It can slow down support teams. It can increase downtime. It can make smart people feel tired and grumpy.
Noise often comes from alerts that are:
- Duplicates: The same issue sends many alerts.
- Low priority: The alert is real, but not urgent.
- False positives: The alert says there is a problem, but there is not.
- Missing context: The alert says something broke, but not why.
- Too sensitive: The system panics over small changes.
A good alert monitoring tool helps reduce this noise. It acts like a smart filter. It does not just shout. It explains.

What Alert Monitoring Tools Actually Do
An alert monitoring tool watches your IT systems. It collects signals from many places. Then it turns those signals into useful alerts.
These tools can watch things like:
- CPU usage
- Memory usage
- Disk space
- Network traffic
- Application errors
- Database performance
- Cloud service health
- Security events
- User experience
But the best tools do more than collect data. They connect the dots. They help answer simple but important questions.
- What is broken?
- How serious is it?
- Who should fix it?
- What else is affected?
- Has this happened before?
That is the difference between noise and visibility.
Operational Visibility Means Seeing the Whole Picture
Operational visibility means you can see what is happening across your IT environment. Not just one server. Not just one app. The whole digital zoo.
Without visibility, teams play guessing games. Is the app slow because of the web server? The database? The network? A cloud outage? A bad release? A raccoon chewing wires? Okay, maybe not the raccoon. But you get the idea.
With strong visibility, teams can see relationships. They can see how one problem affects another system. They can find the root cause faster.
For example, imagine customers cannot check out on your website. The alert says, “Checkout failed.” That is useful, but not enough. A better tool may also show that the payment API is timing out. It may show that the problem started after a new deployment. Now the team has a real clue.
That is powerful. It saves time. It saves money. It saves everyone from scary conference calls.
How Alert Monitoring Tools Reduce Noise
Good alert monitoring tools use several tricks to quiet the storm. These tricks are not magic. But they can feel magical at 2 a.m.
1. Deduplication
Deduplication means the tool combines repeat alerts. If one broken database causes 200 alerts, the tool can group them into one incident.
This is great. Nobody wants 200 messages saying the same thing. One clear message is better.
2. Alert Grouping
Related alerts often happen together. A network issue may trigger alerts from apps, servers, and databases. Grouping puts those alerts into one bundle.
This helps teams see the bigger story. It stops them from chasing tiny clues in random order.
3. Smart Thresholds
Old alert rules can be too simple. They may say, “Alert when CPU is above 80%.” But what if that is normal every morning? What if the system always runs hot during reports?
Smart thresholds learn normal patterns. They alert when behavior is truly unusual. This lowers false alarms.
4. Maintenance Windows
Sometimes systems are down on purpose. Maybe there is a planned update. Maybe a server is being restarted. The monitoring tool should know this.
Maintenance windows silence expected alerts. This keeps inboxes clean during planned work.
5. Priority and Severity
Not all alerts deserve the same level of drama. A full disk on a test server is not the same as a payment system outage.
Alert tools can rank issues by severity. This helps teams act in the right order.

The Role of Automation
Automation is the helpful robot friend of alert monitoring. It can do simple tasks without waiting for a human.
For example, automation can:
- Restart a failed service
- Create an incident ticket
- Notify the right team
- Add logs to an alert
- Run a health check
- Scale cloud resources
- Close alerts when systems recover
This does not mean humans are replaced. It means humans stop doing boring repeat work. They can focus on bigger problems. They can make better decisions.
Automation also makes response faster. If a service crashes, the tool can restart it right away. Then it can tell the team what happened. Nice and tidy.
Context Is the Secret Sauce
An alert without context is like a treasure map with no X. It points somewhere, but not well.
Useful alerts include context. They explain what happened. They show when it started. They show what changed. They show which users or systems are affected.
A strong alert may include:
- The affected service
- The error message
- Recent deployments
- Related alerts
- Recent logs
- Metrics and graphs
- Runbook links
- Owner team details
This makes life easier. The engineer does not need to dig through ten tools. The key facts are already there.
Better Routing Means Faster Fixes
An alert is only useful if it reaches the right person. Sending every alert to everyone is a classic mistake. It creates noise. It also creates confusion.
Good alert monitoring tools support smart routing. They send database alerts to database teams. Network alerts to network teams. App alerts to app teams. Security alerts to security teams.
They can also use schedules. This is called on call rotation. The tool knows who is working now. It alerts that person first. If they do not respond, it escalates.
This keeps incidents moving. It also prevents the “I thought someone else had it” problem.
Dashboards Make the Invisible Visible
Dashboards are like windows into your IT world. They show status at a glance. Green means good. Red means trouble. Yellow means “please look at me before I become red.”
A good dashboard is simple. It does not show every tiny detail. It shows what teams need to know right now.
Useful dashboard views may include:
- Service health
- Open incidents
- Customer impact
- Error rates
- Response times
- Cloud costs
- Security risks
- Team workload
Dashboards also help leaders. They can see trends. They can spot weak areas. They can understand risk without reading 900 log lines.

Cloud and Hybrid Environments Need Extra Care
Many companies now use cloud services. Some use more than one cloud. Many also keep systems in their own data centers. This is called a hybrid environment.
Hybrid setups are flexible. But they can be messy. Data lives in many places. Apps talk to many services. One problem can travel across the whole chain.
Alert monitoring tools help by bringing signals into one place. They collect data from cloud platforms, on premises systems, containers, and third party services.
This unified view is important. It stops teams from switching between many screens. It also helps them notice patterns across environments.
Security Alerts Need the Same Treatment
Security teams also face alert noise. A security system may flag thousands of events. Some are normal. Some are suspicious. Some are serious.
Alert monitoring tools can help security teams by adding context and priority. For example, a failed login may not matter much. But failed logins followed by a successful login from a strange country may matter a lot.
Good tools help connect these events. They make the signal stronger. They help teams respond before small issues become big breaches.
How to Choose a Good Alert Monitoring Tool
There are many tools out there. Some are simple. Some are huge. Some are friendly. Some feel like they were built by a wizard who dislikes buttons.
When choosing a tool, look for features that match your needs.
- Integrations: It should connect to your systems.
- Noise reduction: It should group and deduplicate alerts.
- Smart routing: It should notify the right people.
- Dashboards: It should show clear system health.
- Automation: It should handle repeat tasks.
- Scalability: It should grow with your environment.
- Reports: It should show trends and service quality.
- Ease of use: It should not require a secret handbook.
Also think about culture. A great tool will not fix messy processes by itself. Teams still need clear ownership. They need good runbooks. They need regular alert reviews.
Do Regular Alert Cleanups
Alerts are like closets. If nobody cleans them, they become scary.
Teams should review alerts often. Ask simple questions.
- Did this alert help us?
- Was it too noisy?
- Did it reach the right person?
- Was the priority correct?
- Can we automate the fix?
- Should this alert be deleted?
This habit keeps monitoring healthy. It also teaches the team what “good” looks like.
Final Thoughts
Alert monitoring tools are not just alarm bells. They are traffic controllers. They guide attention. They reduce panic. They help teams see the truth faster.
When alerts are clean, teams work better. Incidents are shorter. Customers are happier. Engineers sleep more. That last one is very important.
The goal is simple. Send the right alert, to the right person, at the right time, with the right context. Do that, and your IT environment becomes less noisy and much easier to understand.
Less chaos. More clarity. Fewer pings. Better days.